llmfit:一条命令测出你的电脑能跑哪些 AI 大模型(附配置建议)
折腾本地 AI 的人大概都经历过这个:好不容易找到一个模型,下载花了一两个小时,结果跑起来发现内存直接爆掉,或者推理速度慢得像老年机在思考人生。我之前也是靠感觉选模型——看看参数量,估一下内存,觉得差不多就拉,碰运气。后来在 Reddit 的 r/LocalLLaMA 看到有人提到 llmfit,说是能扫硬件然后直接告诉你能跑什么,就去试了一下。
这篇写一下 llmfit 的实际用法,顺便给不同配置的人整理了一份参考清单,省掉自己试错的时间。
它到底做什么
一句话说清楚:llmfit 扫你本机的 CPU 核数、内存容量、显卡型号和 VRAM,然后从它内置的 500+ 大模型数据库(覆盖 133 个提供商)里,把你能跑起来的模型全部筛出来,配上四维评分和预估速度,告诉你应该下哪个。
四个评分维度:
- Quality:模型参数量和口碑,越大越好
- Speed:根据你的硬件预估 tok/s
- Fit:内存/显存适配度,分 Perfect / Good / Marginal / Too Tight 四档
- Context:上下文窗口大小
适配等级里,Perfect 是完全没压力跑,Too Tight 就是别想了。Good 和 Marginal 中间那档其实可以跑,就是别同时开浏览器几十个标签页。
它还支持 Ollama、llama.cpp、MLX(Apple Silicon 专用)三种运行时,平台覆盖 macOS / Linux / Windows。工具本身用 Rust 写的,速度挺快,启动几乎不等待。
怎么装
不需要 Rust 环境,装的是编译好的二进制,三种方式都很简单:
Mac(最省事):
brew install llmfitWindows(需要先装 Scoop):
scoop install llmfitLinux / 通用一键脚本:
curl -fsSL https://llmfit.axjns.dev/install.sh | sh装完直接在终端跑 llmfit,默认启动 TUI 交互界面;加 --cli 参数就是纯表格输出。
跑起来长什么样
先用 llmfit system 确认一下它检测到的硬件对不对,这步很重要——如果识别错了,后面推荐的模型全白搭:
TUI 默认界面里,上方一栏是你的硬件信息,中间是按综合评分排序的模型列表,每行显示模型名、量化推荐(比如 Q4_K_M)、预估 tok/s 和适配等级。
几个常用快捷键:
/:进入搜索模式,直接输关键词过滤f:按 Fit 等级筛选,只看 Perfect 或 Goodd:直接下载选中模型(走 Ollama)p:Plan mode,反向查某模型需要啥硬件
CLI 模式用起来:
# 先确认检测到的硬件
llmfit system
# 只看 Perfect 适配的前 10 个模型
llmfit fit --perfect -n 10
# 搜索特定模型
llmfit search "llama 8b"
# 按用途推荐,JSON 输出
llmfit recommend --json --use-case coding --limit 3下面是在一台 16GB 内存、纯 CPU 机器上跑 llmfit --cli fit 的实际输出:
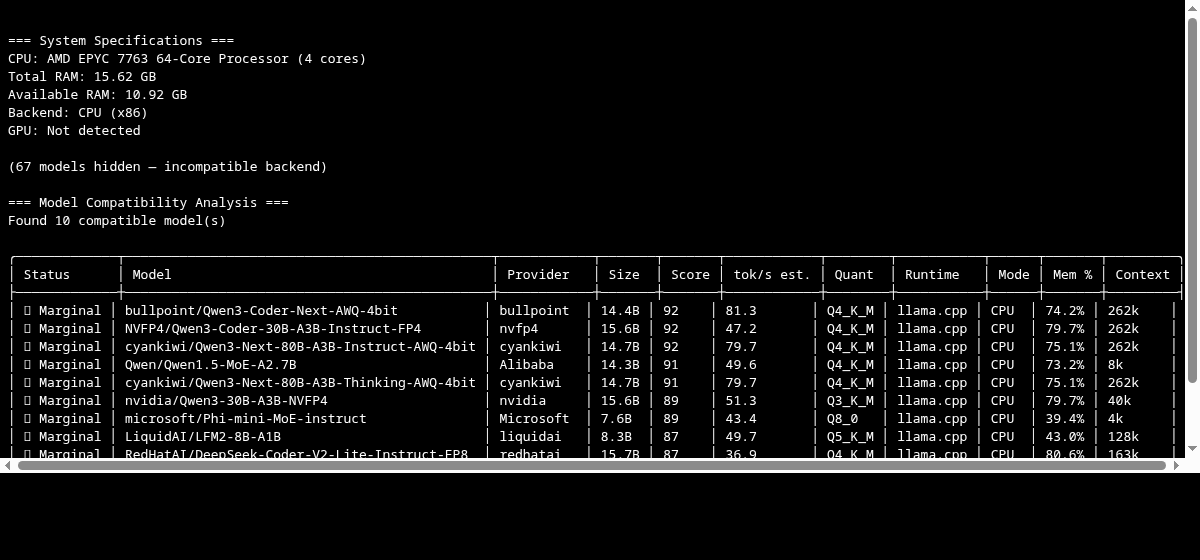
不同配置能跑什么
这节是核心。直接按内存档位说,省掉自己查文档的功夫。
8GB 内存(无独显,纯 CPU)
能跑,但得选小模型。推荐:Qwen2.5-1.5B、Llama-3.2-1B、Phi-3.5-mini。
这几个日常聊天、写代码辅助都够用,不要指望跑 7B 以上的,内存会打满然后开始疯狂 swap,速度从"勉强能用"变成"算了我还是用网页版吧"。
量化推荐 Q4_K_M,这个档位平衡感最好。速度预估大概 20-40 tok/s(CPU x86 基准 70 tok/s,实际随参数量往下压)。
16GB 内存 / 8GB VRAM(RTX 3070、RTX 4060 等)
这个配置开始好玩了,能跑 Good 以上的 7B 级别:Llama3-8B、Qwen2.5-7B、Mistral-7B。
量化推荐 Q5_K_M 或 Q6_K,能保住更多精度。有独显走 CUDA 的话,实际速度落在 60-90 tok/s 这个区间,聊天基本是实时感。
32GB 内存 / 16-24GB VRAM(RTX 3090/4090,或 Mac M2/M3 Pro)
能跑量化版的大模型了,这才是本地 AI 的完整体验:Llama3-70B(Q4_K_M 量化版)、DeepSeek-R1-32B、Qwen2.5-32B。
GPU 预估 70-120 tok/s,Apple Silicon 走 Metal 跑 32B 量化大概在 60-100 tok/s,比很多人想象的快。Mac 这边因为是统一内存架构,32B 的 Q4 放进去没什么压力。
快查表:
| 配置 | 推荐模型 | 量化 | 预估速度 |
|---|---|---|---|
| 8GB 内存,无独显 | Qwen2.5-1.5B / Phi-3.5-mini | Q4_K_M | 20-40 tok/s |
| 16GB 内存 / 8GB VRAM | Qwen2.5-7B / Mistral-7B | Q5_K_M | 40-80 tok/s |
| 32GB 内存 / 24GB VRAM | DeepSeek-R1-32B / Llama3-70B(Q4) | Q4_K_M | 70-120 tok/s |
| Mac M2/M3 Pro(32GB 统一内存) | Qwen2.5-32B / Llama3-70B(Q4) | Q4_K_M | 60-100 tok/s |
Plan mode:反查"跑这个模型需要啥硬件"
这个功能反向操作:给定一个模型名,推算你需要多少内存/显存才能流畅跑,还告诉你能不能 CPU offload。
llmfit plan "Qwen/Qwen2.5-7B-Instruct" --context 8192输出示例(真实跑的):
=== Hardware Planning Estimate ===
Model: Qwen/Qwen2.5-7B-Instruct
Quantization: Q4_K_M
Minimum Hardware:
VRAM: 5.4 GB
RAM: 8.0 GB
Recommended Hardware:
VRAM: 7.1 GB
RAM: 12.0 GB
Feasible Run Paths:
GPU: Yes — est speed: 33.2 tok/s
CPU offload: Yes — est speed: 16.6 tok/s
CPU-only: Yes — est speed: 10.6 tok/s
Upgrade Deltas:
+5.4 GB VRAM -> Good
+7.1 GB VRAM -> Perfect用场景是买电脑之前:先确定要跑哪个模型,用 plan 算出需要什么配置,比在论坛发帖问准多了。
和 Ollama 配合用
llmfit 和 Ollama 搭配是最顺手的组合。TUI 里选好模型,直接按 d 下载到 Ollama,省掉自己查模型名手动 pull 的步骤。
也可以 CLI 拿推荐结果再手动拉:
# 按用途推荐
llmfit recommend --use-case coding --limit 3
# 拿到推荐后手动 pull
ollama pull qwen2.5:7b之前折腾过 Ollama 配合 OpenClaw 做本地记忆搜索,llmfit 先帮你选好模型,再接上 Ollama,整个流程就顺了。如果你在用 OpenClaw,可以看看 OpenClaw CLI 命令指南,有不少和本地模型配合的用法。
几个小坑
显卡识别不准:主要出现在虚拟机或 nvidia-smi 挂了的情况。手动指定内存绕过:
llmfit --memory=24G --cli速度是估算,不是跑分:实际受量化版本、并发、上下文长度影响很大。长上下文(8K+ tokens)场景速度会比估算值低,别把这个数字当成保证。
模型数据库要联网更新:不是完全离线的,离线环境用不了最新模型数据。
Windows 要先装 Scoop:这个包管理器装起来是一条 PowerShell 命令的事,官网直接有,不麻烦。
如果在找 VPS 做本地 AI 部署的基础资源,可以看看这份免费 VPS 清单,有几个跑轻量模型的选项。
试了之后确实省了不少时间,再也不靠感觉下模型了。已经在用 Ollama 的话,顺手装上 llmfit,选模型这步基本就自动化了。
Member discussion