给 Agent 加抬头显示:HUD / 日志 / 任务进度可视化方案盘点(2026)
最近我在折腾 Agent 的时候,越来越受不了一种很熟悉的感觉:
任务已经丢给它了,终端也还在转,但你就是不知道它到底卡在哪。
它可能正在读文件,也可能已经把任务拆给子 Agent 了;可能正在疯狂调工具,也可能只是安静地挂着。最难受的不是等,而是 只能靠猜。
这也是为什么,最近一波 Agent 相关项目开始集体补同一个能力:状态可视化。
有人做成终端底部常驻的 HUD,有人做成浏览器里的控制台,还有人干脆往 LLM observability 那条路走,把 trace、日志、评估、prompt 管理全接起来。表面看起来都像“面板”,但它们解决的其实不是同一个问题。
这篇我不打算泛泛聊概念,而是把现在比较值得看的几类方案拆开讲清楚。你看完之后,基本就能判断自己需要的是哪一种:
- 想看 Agent 现在正在做什么
- 想看整套系统 当前是什么状态
- 想追踪它 为什么做错、以后怎么优化
如果你最近也在玩 OpenClaw、Claude Code、Codex,或者已经开始给 Agent 接浏览器、接工具、接子任务,这个问题其实早晚都得面对。
为什么 Agent 时代一定会冒出“状态面板”需求
传统聊天机器人其实没那么需要这东西。
你问一句,它回一句。过程虽然也在跑模型,但大多数人不关心中间发生了什么,因为中间本来就没有太多可看的。
可 Agent 不一样。
Agent 一旦开始:
- 调用工具
- 打开网页
- 读写文件
- 拆分 todo
- 启动子 Agent
- 定时跑任务
- 连真实机器权限
它就已经不是“对话框”了,而更像一个会自己执行动作的小系统。
既然是系统,就一定会有两个新问题冒出来。
1)我怎么知道它没卡死
尤其是长任务最明显。
如果一个 Agent 10 秒没回你,可能是正常思考;但如果 5 分钟都没动静,你很自然就会开始怀疑:
- 是不是死循环了
- 是不是网页元素没找到
- 是不是上下文快爆了
- 是不是某个子 Agent 还在后台跑
没有状态面板时,这些都只能靠猜。
2)我怎么知道它到底做了什么
这不只是“好奇”,很多时候还是安全感问题。
尤其你把 Agent 接进文件系统、浏览器、shell 之后,用户会天然想知道:
- 它刚才用了什么工具
- 它修改了哪些东西
- 它是在哪一步开始跑偏的
- 它为什么突然停住
所以状态可视化这件事,本质上不是“做个酷炫 UI”,而是 把黑箱拆开一点,让人敢继续把任务交给它。
先别急着装,先把 3 类需求分清
很多人一上来就搜“Agent dashboard”“AI observability”“HUD”,然后越看越乱。根本原因不是工具太多,而是需求没拆开。
我现在更愿意把这类需求分成 3 层。
第一层:我想知道它现在正在做什么
这是最直觉的一层。
比如你在终端里跑 Claude Code、Codex 之类的 Agent,真正想知道的往往是:
- 当前模型是谁
- 上下文还剩多少
- 刚刚调用了什么 tool
- 有没有 subagent 在跑
- todo 完成了几项
- 现在到底是在读、在写,还是在搜
这种需求最适合 HUD。
重点不在“历史回放”,而在于:你一抬眼就能看到当前状态。
第二层:我想看整套 Agent 系统现在是什么状态
这已经不只是当前窗口的问题了,而是更像运维后台:
- 现在有多少 session
- 哪个任务还在跑
- 子 Agent 有没有结束
- 哪个 cron 失败了
- 节点是不是在线
- 日志里有没有异常
- 权限策略是不是配对了
这种更适合 Control UI / Web 控制台。
它解决的是“系统可见性”,不是单一终端的状态条。
第三层:我想知道它为什么错,以及怎么持续优化
这就更深一层了。
比如你开始关心:
- 某类任务为什么总答歪
- 某版 prompt 为什么效果下降
- 哪条 trace latency 特别高
- 换模型之后到底有没有提升
- 哪个步骤最容易失败
这时候你需要的就不是轻量 HUD,也不是普通后台,而是 Observability 平台。
像 Langfuse、Phoenix 这类工具,重点已经不是“显示状态”,而是“收集链路、对比结果、支持复盘和优化”。
把这三层分清,后面的选型就一下顺了。
方案一:终端 HUD,最适合个人高频使用
如果你本来就是命令行重度用户,那我觉得最值得优先上的,通常不是大而全的平台,而是先给终端加一个 HUD。
我这次重点看的是 claude-hud。这个项目最近讨论度挺高,原因也很简单:它的思路特别克制。
它不是另开一个网页,不是要求你切 tmux,也不是再起一个重前端,而是 直接把状态线钉在 Claude Code 的终端里。
从项目页面和 README 描述来看,它目前主打的就是把几类最关键的信息实时露出来,比如:
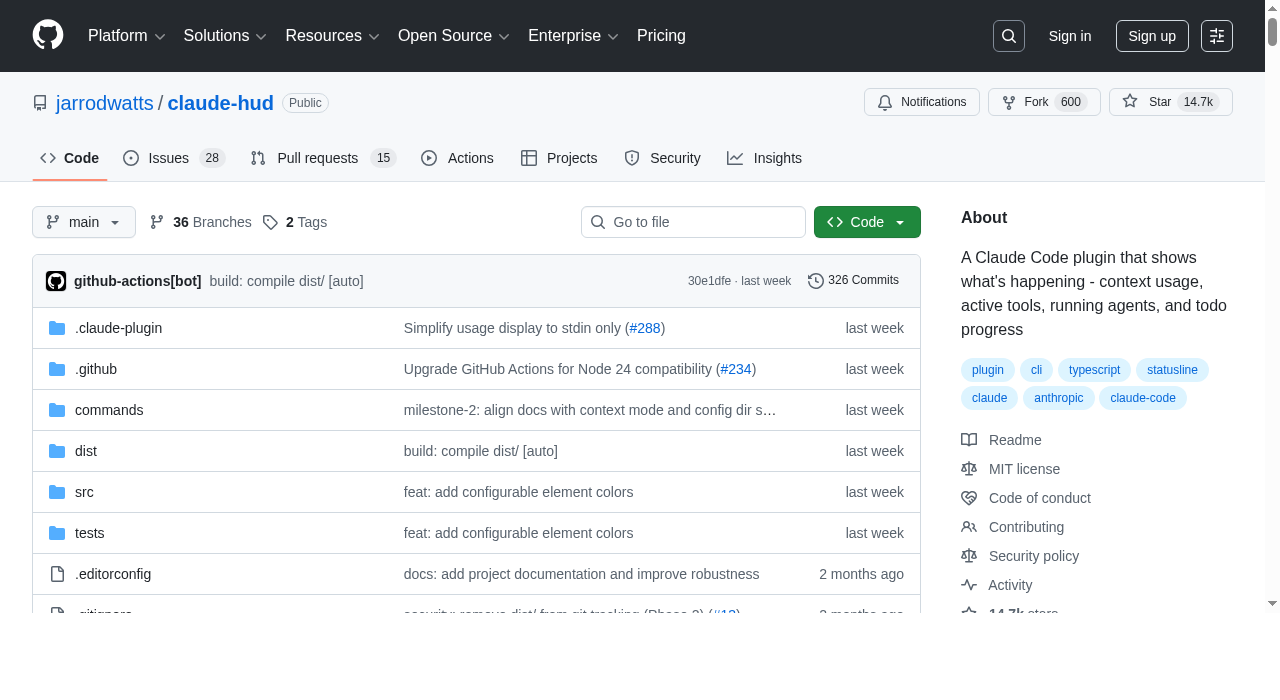
- 当前模型
- context 占用情况
- usage 限额
- tool activity
- running agents
- todo progress
- session duration
- 项目路径和 git 分支
这类 HUD 最打动我的地方,不是“信息多”,而是 信息离你够近。
以前 Agent 在后台跑任务时,终端给你的反馈往往很零散。它也许会偶尔吐几行输出,但你还是很难形成完整判断。加上 HUD 之后,你会明显感觉 Agent 没那么黑箱了。
尤其是下面几类信息,一旦实时挂在眼前,体验会立刻不一样。
Context 和 usage
这个真的太关键了。
很多 Agent 任务跑着跑着开始降智,或者突然变慢,根本原因不是“模型变傻了”,而是上下文快撑满了。HUD 把 context 百分比直接亮出来之后,你会更早知道问题在哪,而不是等回答开始崩才反应过来。
如果你用的是有订阅限额或使用窗口的产品,usage 也很有价值。你不用再靠感觉估算自己是不是快打满了。
Tool activity
这个是最直接的安全感来源之一。
你能看到它刚才是在 Read、Edit、Grep,还是在调用别的工具。虽然这不等于完整审计日志,但至少你知道它现在大致在做哪类动作,不会只有一个光标在那儿闪。
Agent / Todo 进度
一旦任务开始拆分,这两个信息非常值钱。
有没有 subagent 在后台跑、todo 到底做到了第几项、是不是已经从“探索”切到“执行”了,这些东西对判断任务是否正常推进特别重要。
HUD 的优点和短板
HUD 的优点很明显:
- 上手快
- 改造轻
- 不需要额外开后台页面
- 对终端用户体验提升立竿见影
但短板也一样明显:
- 它主要服务“当前这一眼”
- 不擅长做长期回放
- 不适合做多 session 总览
- 也不适合做团队级分析
换句话说,HUD 很像汽车仪表盘。你开车时一直离不开它,但它不等于行车记录仪,更不等于车队调度系统。
所以如果你的核心问题只是“我现在看不清它在干嘛”,先上 HUD 往往是最划算的一步。
方案二:控制台 / Web 控制面板,更像 Agent 管理后台
如果说 HUD 解决的是“当前窗口可见”,那第二类方案解决的就是“整套 Agent 系统可见”。
这类方案里,我觉得最值得写给 OpenClaw 用户看的,还是 OpenClaw 自己的 Control UI。
我翻了官方文档之后,感觉它现在的定位已经不只是一个“聊天网页壳”,而是明显在往 Agent 控制台 这个方向长。
按官方文档描述,它这套浏览器面板能做的事情其实不少,包括:
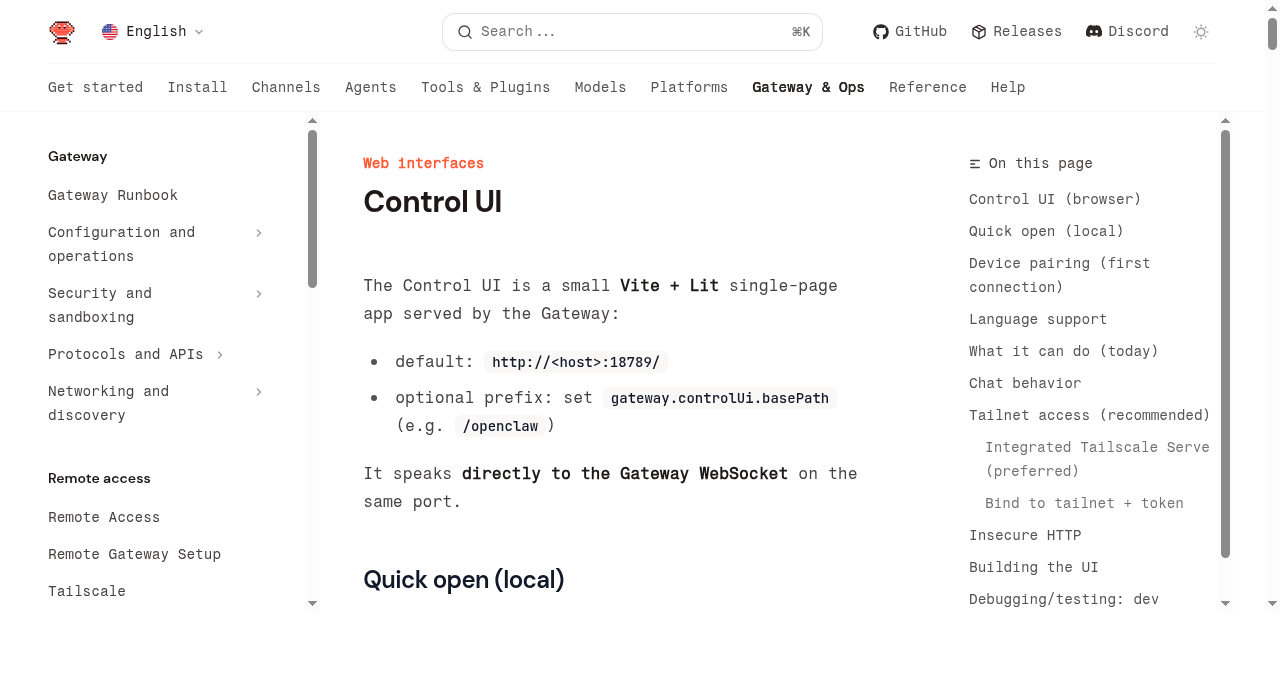
- 看 chat 历史和 live tool output cards
- 看 sessions 列表
- 管理 cron jobs 和运行历史
- 看 skills 状态
- 看 nodes 列表
- 配 exec approvals
- 读写 config
- tail logs
- 查看 health / models / status 这类调试信息
这意味着它解决的已经不是“终端里这一轮任务在干嘛”,而是:
我的整套 OpenClaw 系统现在是什么状态。
为什么这类面板对 OpenClaw 这种系统特别重要
因为 OpenClaw 天生就不是单纯的一问一答。
你一旦开始用这些能力:
- subagents
- cron
- browser
- exec
- node
- skills
- 多 session
系统就会很快从“一个聊天入口”长成“一个能调度很多动作的 Agent 中枢”。
这个阶段,只靠终端是很难舒服管理的。
我觉得 Control UI 最有价值的地方有 3 个
1)会话和任务一眼能看清
你不需要再只盯当前终端窗口。
比如现在到底有哪些 session 活着、哪个子 Agent 还在跑、哪个任务已经结束、哪个会话开了不同配置,这些在 Web 面板里天生比命令行更适合总览。
2)日志、权限、节点这些系统信息终于聚合了
文档里提到的 logs tail、nodes、exec approvals 很关键。
这说明它不是只想给你做一个“能聊天的网页端”,而是想把 Agent 真正跑起来之后最容易分散的那些系统信息,重新收拢到一个入口。
特别是你开始把 Agent 接触到真实主机、真实浏览器、真实自动化任务时:
- 节点在线没在线
- approval 怎么配的
- 最近日志有没有炸
- 某个 cron 是不是一直报错
这些东西都会变得越来越重要。
3)它很适合排错
排错的时候,Web 控制台的优势会一下出来。
终端当然也能查,但很多时候你想看的不是一行命令结果,而是一个更完整的上下文:
- 某个 run 前后发生了什么
- 某次工具输出长什么样
- 当前配置是什么
- 哪个 session 改了什么设置
这种时候,Control UI 明显比纯 CLI 更顺手。
它也不是万能的
当然,这类控制面板再好,也不等于完整 observability。
它擅长的是:
- 会话管理
- 实时状态查看
- 权限与配置入口
- 日志观察
- 系统排错
但它不太擅长的是:
- prompt 版本对比
- trace 级别分析
- 数据集评估
- 长期质量追踪
- 实验和迭代管理
所以它更像“Agent 管理后台”,而不是“LLM 研发分析平台”。
方案三:Langfuse / Phoenix,这已经不是小面板,而是 LLM 调试系统
第三类方案就完全是另一种重量级了。
我这次主要看了 Langfuse 和 Phoenix。它们都不只是“给你看日志”,而是在做一件更工程化的事:
把 Agent / LLM 应用运行过程中发生的链路采集下来,变成可分析、可回放、可评估的数据。
这和 HUD、Control UI 的思路完全不是一个层级。
Langfuse 更像什么
从官方介绍看,Langfuse 这条线已经非常完整了。它不只是 tracing,还把很多 LLM 工程常见需求打包在一起:
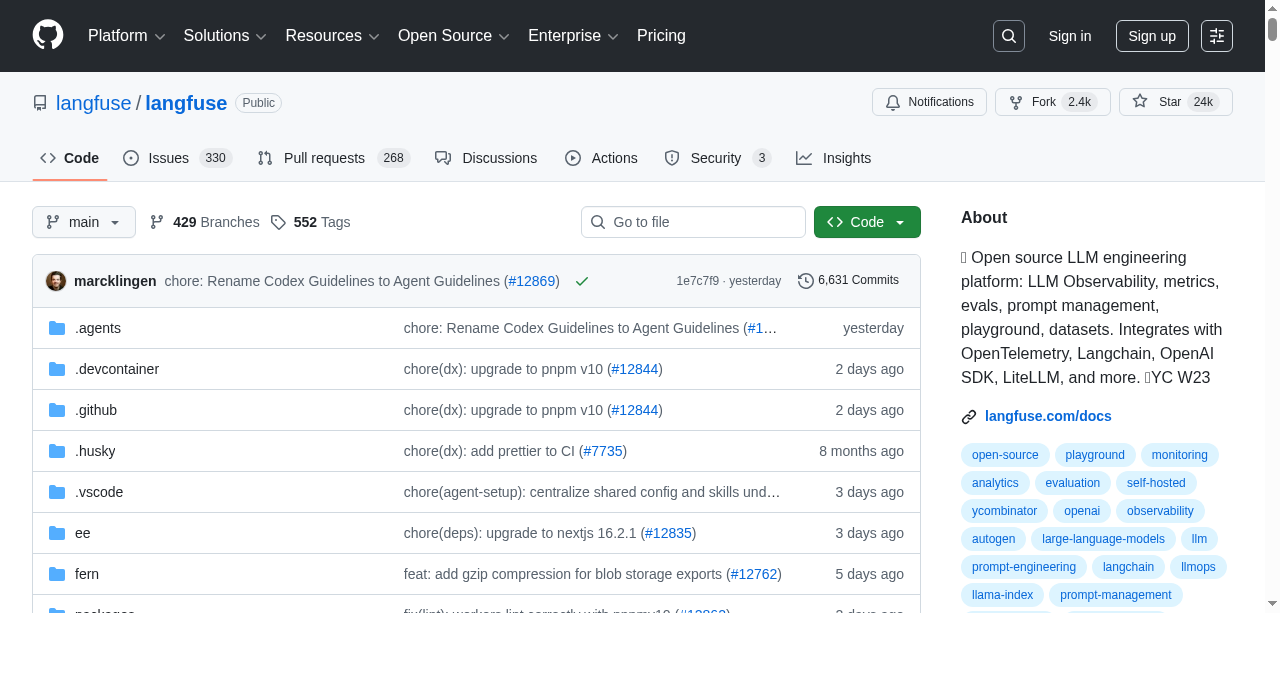
- tracing
- prompt management
- evaluations
- datasets
- playground
- API / SDK 集成
而且它明确提到可以追踪的东西不只是模型调用本身,还包括 retrieval、embedding、agent actions 这些链路。
这很关键。
因为真正难排查的,往往不是“模型为什么回了这句话”,而是:
- 它检索拿到了什么
- 中间哪个步骤出错了
- 哪个工具动作拖慢了整体时间
- 某个 prompt 版本是不是引入了退化
Langfuse 这种平台的价值就在这:你看到的不只是结果,而是一整条执行过程。
如果你做的是线上 Agent 应用,或者已经开始多人协作调 prompt、复盘失败案例,那它这套思路会很顺。
Phoenix 的味道又不太一样
Phoenix 也做 tracing、evaluation、datasets、experiments、prompt playground,但它更强调 open telemetry、experimentation 和 troubleshooting。
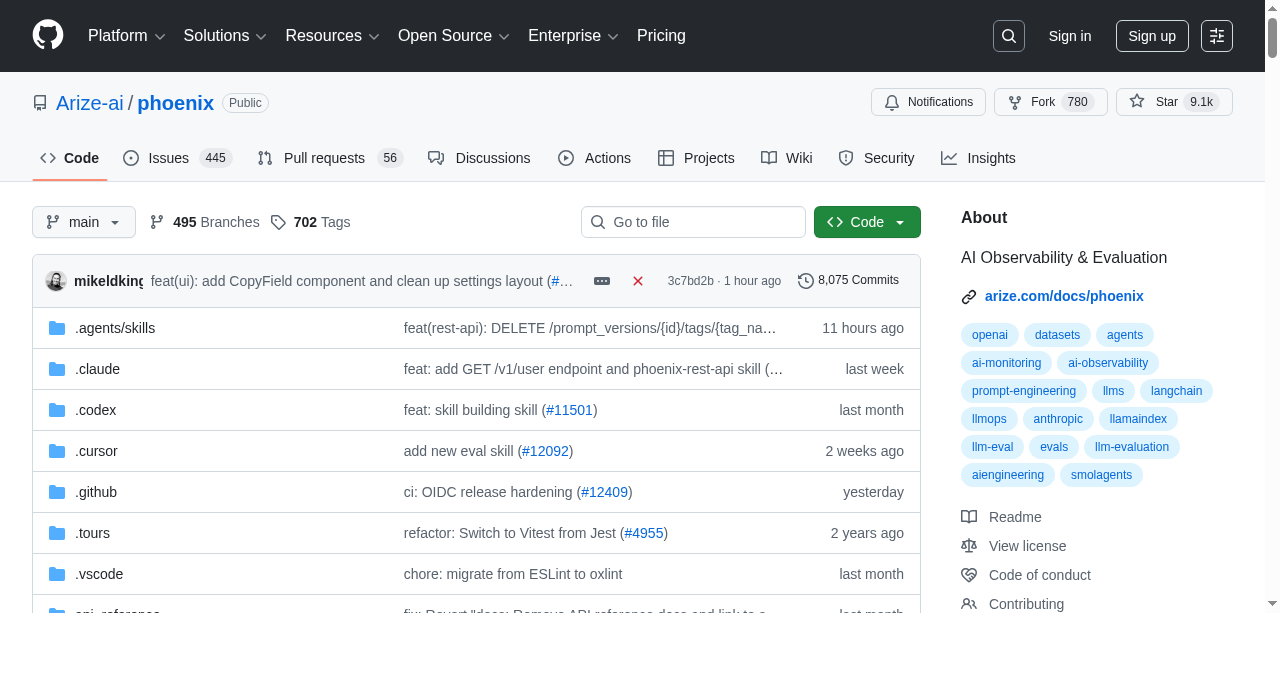
这个区别说大不大,说小也不小。
Langfuse 给我的感觉更像一整套 LLM 工程平台;Phoenix 则更有那种“把 tracing 融进你现有工程体系”的味道。
特别是如果你本来就习惯用 OpenTelemetry、trace、observability 这一套工程语言去排问题,那 Phoenix 会比较对味。
它对不少框架和 provider 也都有现成适配,这让它在工程团队里会更好落地一些。
这类 observability 平台什么时候才值得上
我自己的判断很简单:至少满足下面两条,再认真考虑。
1)你的 Agent 不是一次性玩具
如果你只是自己本地玩玩,一个任务跑完就算,这时候直接上 Langfuse / Phoenix 往往太重。
因为你真正缺的可能只是“当前状态可见”,不是“长期链路可分析”。
2)你已经开始关心“为什么好 / 为什么坏”
一旦你开始反复问这些问题:
- 为什么某类问题老失败
- 为什么换了 prompt 以后效果更差
- 为什么不同模型表现差这么多
- 为什么某条链路总是慢
那 observability 才真正有意义。
否则很容易变成:任务都还没跑顺,先给自己加了一套要维护的后台。
这不是不行,只是很多时候不划算。
一张表看懂:HUD、Control UI、Observability 到底差在哪
| 方案类型 | 代表工具 | 最适合解决的问题 | 优点 | 局限 |
|---|---|---|---|---|
| 终端 HUD | claude-hud | 我现在看不清 Agent 在干嘛 | 轻量、实时、离终端近 | 不擅长历史回放和多会话总览 |
| Web 控制台 | OpenClaw Control UI | 我想看整套 Agent 系统当前状态 | session、cron、logs、nodes、approvals 聚合在一起 | 不是完整的 trace / eval 平台 |
| Observability 平台 | Langfuse、Phoenix | 我想知道它为什么出错、如何长期优化 | tracing、prompt、evaluation、dataset、实验对比更完整 | 部署和维护成本更高 |
这三类方案不是互斥关系,别拿错工具就行
我现在越来越觉得,Agent 可视化最容易走偏的一点,就是把所有工具都当成同一类东西。
其实更合理的理解是:
- HUD 负责眼前可见
- Control UI 负责系统可见
- Observability 平台 负责链路可追踪
这三层不是互相替代,而是各管一段。
你真正需要避免的,不是“装太多”,而是 拿错层级的工具解决错误的问题。
比如:
用 HUD 解决长期质量分析
这肯定不够。
HUD 适合告诉你“现在发生了什么”,不适合告诉你“过去一个月为什么这类任务表现下降”。
用 Langfuse 解决当前窗口是不是卡住
这就太重了。
你只是想看它现在是不是还在读文件、是不是 subagent 还没结束,这时候一个轻量 HUD 反而最舒服。
用普通日志页解决 Agent 任务进度感知
也未必顺手。
日志当然有信息,但“能查”和“好看懂”是两回事。Agent 真正让人焦虑的,往往不是没日志,而是日志太散、不成形。
如果是我,我会怎么选
如果让我自己给不同类型用户配方案,我大概会这么分。
1)个人用户 / 终端重度玩家
先上 HUD。
原因最简单:投入最小,反馈最快,今天装今天爽。
你不需要先搭大平台,不需要改很多架构,只要先把“现在发生了什么”看清楚,体验就能立刻改善。
2)OpenClaw / 自托管玩家
优先看 Control UI。
因为你碰到的问题通常已经不是单一窗口问题,而是:
- 多 session 怎么看
- cron 怎么看
- node 怎么看
- logs 怎么看
- approvals 怎么看
这时候 Web 控制台的收益会比单纯 HUD 更大。
如果你最近看过我前面写的《OpenClaw 浏览器实战(2026)》《OpenClaw 权限设置教程(2026)》和《OpenClaw 多 Agent 配置指南》,你应该已经能感受到:一旦功能多起来,没有一个集中入口真的会越来越难管。
3)做线上 Agent 应用 / 团队协作的人
再考虑 Langfuse / Phoenix。
这时你真正缺的已经不是“当前状态看不见”,而是:
- trace 不能回放
- prompt 版本不好比较
- eval 缺失
- 数据集和实验没法沉淀
也就是说,你进入的已经不是“玩 Agent”的阶段,而是“把 Agent 当系统运营”的阶段。
我自己的结论
如果你问我一句最实在的话,我会这么说:
别一上来就追求最重的 observability,先把最让你焦虑的那层黑箱拆开。
- 看不清当前动作,就上 HUD
- 看不清整套系统,就上 Control UI
- 看不清长期问题和质量变化,再上 Langfuse / Phoenix
很多时候,问题不是“没有工具”,而是顺序错了。
写在最后
我现在越来越觉得,2026 年继续把 Agent 当成一个“发出指令然后祈祷它自己搞定”的黑箱,其实已经有点过时了。
Agent 一旦开始接工具、接浏览器、接文件系统、接子任务,它就已经不是简单聊天机器人了。既然它是系统,就应该有状态;既然有状态,就应该让人看得见。
这也是为什么我会越来越重视这些状态面板、控制台和可追踪链路的工具。
不是因为它们“高级”,而是因为只有看得见,你才敢把更多真实任务交给它。
先让 Agent 变强,不一定会更安心; 但先让 Agent 变透明,通常一定会更好用。

Member discussion